|
|
Christopher C. Hartwell
Parker H. Sternbergh
Tulane University
Abstract
This project examines the problem of search engine accessibility in terms
of what is commonly called "the invisible web." As the problem pertains to
community resource web sites, many are presently available on the internet
with content that is not indexed by the major search engines. This makes
the resources more difficult for consumers to find.
This project examines current and past research regarding search engine
accessibility and search engine optimization. It goes on to demonstrate a
method for making invisible web data (in the form of community resources)
accessible to the major search engines. It is a project designed to aid
the community service organization professional in implementing their
organization's web site in order to better serve all stakeholders. The
outcome of our project is a web site that provides community resource data
to the public through the major search engines, and we present limited
qualitative data which demonstrates its effectiveness.
Acknowledgements
The authors would like to acknowledge the major search providers Google
and Yahoo! for providing their search services to the public free of
charge. We also acknowledge the many contributions of authors in the field
of search engine optimization and search engine marketing, who over the
years have helped to guide the ethical (or "white hat") practice of search
engine optimization. These contributors are not limited to Danny Sullivan
(Founder and Editor of
Searchenginewatch.com), Jill Whalen (Owner,
Highrankings.com), Brett Tabke (Owner,
Webmasterworld.com) as well as the
many members who post in the forums of
Webmasterworld.com. We would also
like to acknowledge the Louisiana Office for Addictive Disorders for
putting together the database of treatment facilities on their web site,
and
Tulane University
School of Social Work for accepting this topic as a Capstone Project.
Problem Formulation
The growth of the internet brings many opportunities for non-profits and
community service organizations to reach their clients. When organizations
take on the task of implementing a web site, decisions must be made about
the budget for the site, the graphical design of the site, which
information to include on it, and how to present the information to the
public. Furthermore, significant thought must be given to where financial
resources should be spent. It is necessary to determine what should be
spent on the actual design of the site, as well as what should be spent on
marketing the site.
There are many ways to make community resources available to the public
through web sites. One way is to raise awareness of a web site through
advertising. Organizations commonly place ads on television, billboards,
promotional products, and radio in order to raise awareness of themselves
and the services they provide. This form of advertising can bring direct
traffic to a web site, because the public may remember the web address and
type it directly into a browser. Another way to make these resources
available to the public is through advertising on other web sites. Ads
placed on web sites are usually hyperlinked to the site that the ad is
promoting, bringing the user directly to the site when the ad is clicked.
While both methods are commonly used by organizations to raise web site
visibility or awareness, search engines have frequently been overlooked
because they are poorly understood, even by many web site designers. In
our discussion, we will sometimes mention terms that traditionally aren't
a part of the educational background received by professionals who are
employed in community service organizations. In order to facilitate better
understanding of our project in this field, we have included an appendix
with definitions that correspond to the words in bold print within this
text.
In order to gain some understanding of how complex searching the web has
become, one must consider the increases in usage. In 1996, there were 7.5
million searches on the web. (Brin, Page, 1998). By 2000 the number
increased to 41 million (Davis, 2002), and according to
Nielsen//Netratings, in January 2005, there were 4,086,000,000 searches on
the web. Between 1994 and 1997, the average number of documents available
to a web searcher increased 20 fold, and today, on April 16, 2005, Google
reports an index of 8,058,044,651 documents that it searches (Brin, Page,
1998; Google, 2005). In February of 2004, Nielsen//Netratings reported
that 39 percent of Americans used a search engine during January 2004, and
that the 114.5 million unique users, represented 76 percent of the active
online U.S. population.
The increasing usage and size of the web has started many new industries.
There are specialists who study huge compilations of web search query logs
in order to understand aggregate user web search behavior and query
patterns. The objective is to design sites that better anticipate how a
user searches for data and to incorporate that knowledge into site design
and search engine optimization (SEO) strategies. Silverstein and Henzinger
(2002) conducted one of the largest of such studies. The subject of the
study was the Alta Vista Search Engine. The group studied a query log with
one billion search request entries and 285 million user sessions over a
six week period (Silverstein, Henzinger, 2002). Silverstein and Henzinger
(2002) discovered that "web users differ significantly from the user
assumed in the standard information retrieval literature." The group found
out that users in the log typed short phrases (instead of word strings
connected by "AND" and "OR" for example). In another study, Joachim (2002)
determined that there was an average of 2.35 words in the average query.
Users typically looked at the first ten items in the retrieval list
(Silverstein, Henzinger, 2002). In fact, 85% looked only at the first
screen of a query and very few queries were revised (Silverstein,
Henzinger, 2002). Healthcare has been a primary search topic on the web.
By 2002 healthcare sites were among the fastest growing page categories on
the web (Davis, 2002). In a statistically significant poll conducted in
2001, 40% of respondents reported using the internet to get advice or info
about health or healthcare (Baker, Laurence, Wagner, Todd, Singer, Sara,
Burndorf, Kate 2003).
In addition to the increasing size of the web and its usage, hardware and
crawling technology must keep up with the staggering growth. Search
engines have multiplied and become very competitive. According to
Nielsen//Netratings, as of January 2005, Google had 47% of the market
followed by Yahoo at 21%. Search engines may be publicly accessible or
private and each has its own policy and method of crawling the Web. Each
search engine also has varying technical ability to keep up with the size
and volume of traffic on the web.
Search engines do not index sites equally (Brin, Page, 1998; Lawrence,
Giles, 2000). Some of the best academic literature on this subject has
come out of Stanford University and the founders of Google. The founders
of the most popular search engine, Google, created the search engine while
at Stanford University. Their main focus was a
method of determining the importance of a web page in relation to the
user's query. The method that evolved as a determination of importance of
a web page is still in use today, represented by a factor that Google
calls PageRank. PageRank responded to the challenges of web growth, the
increase in queries and indexed pages, and the problem of finding
meaningful responses to queries. PageRank has been widely studied and has
become a respected standard in the industry. Because the principles of
PageRank have been applied amongst the major search engines, it was
important that we study it and incorporate its principles into our web
site design methodology. In Page's definitive 1998 paper discussing the
rapid growth of the World Wide Web, they did a random sample of servers to
investigate the amount and distribution of information on the Web. They
pointed out that in there were approximately 800,000 million pages and
over 3 million servers. At that time, the largest search engine only
covered 30% of the web (Brin, Page, 1998).
The internet contains a mix of viable academic and reliable resources as
well as less credible commercial information and resources. Brin and Page
(1998) determined at the time of their study, that 83% of search engines
had commercial content. They further determined that about 6% of servers
have scientific and, or educational content. At the time it was found that
overlap between search engine results was low (Brin, Page, 1998). In their
study, Brin and Page (1998) found that it took 57 days to get a page
registered in a search engine, the only way the site would be available
for indexing. Today, this is not the case, modern day search engines index
sites rapidly once they are found through crawling hyperlinks.
For the scope of this project we examined current knowledge of search
engine accessibility and search engine optimization. Many community
service organizations, from private therapists, to government agencies
have web sites; and many people are now using search engines to find these
web sites (Sullivan, 2005). The problem which occurs is that community
resource web sites are not always designed with search engine
accessibility and, or optimization in mind. When this happens, potential
clients are not able to find the information that they are looking for.
Often times, data is contained in an online database such as the community
resource data for Southeastern Louisiana accessible through the Via Link
web site (http://www.vialink.org) and the Louisiana Office for Addictive
Disorders (LOAD) database of treatment facilities (http://www.dhh.state.la.us/offices/locations.asp?ID=23).
Databases such as these contain a large amount of useful information
including names and descriptions of local agencies; but if users don't
already know the organization's web site address or happen upon the site
through a hyperlink from another site, the data never gets found. This
phenomenon is commonly known as "the invisible web."
The invisible web consists of online databases, excluded web pages, and
many types of web pages that are actively generated by the server upon the
user's request (as opposed to "static" html documents) (UC Berkley, 2004).
Many private networks (usually password protected) and private databases
are also considered a part of the invisible web, but for our purposes we
will focus on the content that is intended to be available to the public.
This invisible web exists because of present day limitations to what
search engines add to their index. A search engine's "index" is its own
database of web pages that it draws from in order to produce search
results. It finds data by "spidering" or "crawling" web pages from
hyperlink to hyperlink. Many invisible web databases are accessible only
through their respective database search forms; therefore the search
engine spider has no way of accessing the data (Raghavan, Garcia-Molina,
2000; Lawrence, Giles, 2000).
The goal of this project is to illustrate a method of making an "invisible
web" database more accessible to search engines. The need for solutions to
the community resource gap in the search engines is evidenced by many web
sites that provide community resources online, yet do not make these
resources accessible to search engines. For the purpose of our project, we
have used the Louisiana Office of Addictive Disorders' database of
Louisiana's substance abuse clinics, treatment centers, and prevention
programs as an example of an invisible web database. The database uses
query strings in the URL's of the resources available, and does not
provide a way for search engine spiders to index the resources. When web
sites are designed without search engine accessibility in mind, this data
is harder to get to because one needs to know exactly where to go in order
to access the data - which in this case is the following web address:
http://www.dhh.state.la.us/offices/locations.asp?ID=23.
The web site we
created in order to demonstrate our solution to the invisible web problem
is "Louisiana Addiction Resources" (LAR) and it can be found at http://louisiana-addiction.com.
The objective of this project is to provide awareness of search engine
accessibility issues, a method of solving the problem, and guidelines for
community service organizations to implement an optimized and accessible
web site.
Methodology
Our project was done as a descriptive design with limited qualitative
analysis. As evidence that accessibility works, we will present
qualitative data that internet users typed into search engines. The data
presented are queries which resulted in those users finding our web site.
In this section we will discuss common themes related to search engine
accessibility and optimization that we used to construct our community
resource web site. Our first task was to become familiar with the subjects
of "the invisible web" and "search engine optimization." The invisible web
exists because documents and data aren't accessible to the search engine
for a number of possible reasons, and the first step in creating our web
site was to outline a static hyperlinked structure that the search engine
spiders could follow. Here is an outline of the link structure we used:
I. Home Page
a. Louisiana Parishes Page (with links to a page for every parish in the state).
i. Individual Parish Pages (with links to a page for each parish's resources)
1. Resource 1
2. Resource 2
3. Resource 3
4. Etc.
While accessibility is the first factor in making internet resources
available through the search engines, without optimization, a site can
still fail in its purpose. The concept of optimization is a sub-topic of
accessibility that is almost just as important; because without
optimization, frequently, even accessible documents aren't able to be
found by the searcher. We will discuss optimization further in the next
section.
Search engine spiders do not presently crawl many types of "dynamic" web
pages for many different reasons (dynamic refers to types of web pages
which are created by the server upon the user's request) (UC Berkley,
2004; Raghavan, Garcia-Molina, 2000; Lawrence, Giles, 2000). Dynamic web
pages are often a product of database driven web sites; and since most
community resource data available through government web sites and online
directories is taken from databases, much of this content is not crawled
by search engines. As mentioned earlier, two examples of dynamic databases
that are presently not indexed by search engines are the Louisiana Office
of Addictive Disorders (LOAD) database (http://www.dhh.state.la.us/offices/locations.asp?ID=23)
and the Via Link database (http://www.vialink.org/index1.html).
The solution we propose is to have static hyperlinks that lead to a
directory of the database's content. In order to accomplish this for the LAR web site, we created a taxonomy for organizing the resources in
directory format. Examples of similar solutions, on a much larger scale,
are DMOZ.org (The Open Directory Project),
Google Directory and
Yahoo!
Directory. All are static, crawl-able, taxonomies of web sites covering
almost every topic available on the internet. The LAR web site we have
created in order to illustrate this technique, is an all inclusive
directory of the same data that is contained in the LOAD database. The
information contained within LAR is in the format of static html pages,
linked together by static hyperlinks, which are easily crawled by present
day search engine technology, making the information more widely
accessible to the public.
Database query strings and session ID's are one of the most common
barriers to accessibility for search engine spiders when attempting to
index dynamic content. Search engine spiders are instructed not to follow
these types of hyperlinks because of a multitude of different problems
that can occur (UC Berkley, 2004). Here are two examples of URL's with
database query strings (the first from the Via Link web site, and the
second from the LA Office of Addictive Disorders web site):
http://unity.servicept.com/cp/findhelp/findhelpbasic.php?sid=5095761fc45efe1fb945d37a67ef85bd&rand=1113213131
http://www.dhh.state.la.us/offices/locations.asp?ID=23&Detail=151
Database query strings and session ID's are characterized by question
marks (?), and equal signs (=) in the URL, often having "?ID=" in that
particular order. A typical static web page URL will look similar to this:
http://louisiana-addiction.com/parishes/lincoln-parish.shtml
There are more characteristics to consider when optimizing URL's, and we
will discuss those in the next section.
Optimization Guidelines
Next, we had to become familiar with the important concepts and methods
involved in designing well-optimized web sites. The guiding principle of
search engine optimization is to design a web site that shows up in the
search engines for queries related to its content. Not only does a
well-optimized page tell the search engine what the page is about, but it
also has links from other pages on the internet that indirectly serve to
tell the search engine what that page is about. With that being said, we
can divide the concept of optimization into two distinct processes,
"Off-Page Optimization" and "On-Page Optimization." Recent advances in
search engine technology have taken into account historical data in their
method of ranking search results as well (Anurag, Cutts, Dean, Haahr,
Henzinger, Hoelzle, Lawrence, et. al. 2005). Although worth mentioning, we
will only go into brief detail regarding this factor since it is so new
and so little is known about it, and also because it can get more
technical than is appropriate for this paper.
On-Page Optimization
Google maintains much more information about web documents than typical
search engines. Every hitlist includes position, font, and capitalization
information. Additionally, we factor in hits from anchor text and the
PageRank of the document. Combining all of this information into a rank is
difficult. We designed our ranking function so that no particular factor
can have too much influence (Brin, Page 1998, p.1).
Using Brin and Page's earlier statements, we can see that many different
aspects of text on a web page are taken into account when determining
search relevance. A simple rule of thumb to use is, "use what makes most
sense to the user" (while keeping the search engine in mind, of course).
On page optimization is something that many sites do well without even
intending to do so. One aspect of importance is having a relevant page
title. The title goes within the "head" section of the html document. It's
enclosed by the <title></title> tag, and is one of the most important
places for a document's descriptive keywords to be located. The title
should be relevant to the text on the page. Having the text on the page,
with the most important words in bold, italics, or underlined is another
way that pages are well optimized without intending to be.
Proximity of words on a page also plays an important factor in the ranking
of web pages in search results. For example, a search for the phrase
"marriage counseling" will (with all other factors being equal) pull up a
page that has "marriage counseling" in its text before a page in the
results that has "marriage and family counseling" in its text. The
proximity of words plays an important role in the search results as
explained below. For a multi-word search, the situation is more complicated. Now multiple
hit lists must be scanned through at once so that hits occurring close
together in a document are weighted higher than hits occurring far apart.
The hits from the multiple hit lists are matched up so those nearby hits
are matched together. For every matched set of hits, a proximity is
computed. The proximity is based on how far apart the hits are in the
document (or anchor) but is classified into 10 different value "bins"
ranging from a phrase match to "not even close" (Brin, Page 1998, p.1).
Here Brin and Page discuss how proximity of words affects relevancy in
search. Again, this is another factor involved in search engine
optimization that many web sites will accomplish without having the
original intention of optimizing the site. It's simply another factor to
be aware of when formatting content and subject matter on a web page.
Sites should be well-organized with pages devoted to individual topics and
optimized for those topics. For example, a web page devoted to "Sports
Cars, Grocery Stores, and Mental Health Counseling" isn't likely to show
up for any of those three concepts in a search engine. A search engine's
goal is to search the way that people search so that it find's the results
that people want to find. Therefore, a good rule of thumb is to design the
web site with usability in mind. Just as you are telling a user where to
go in order to find information on your web site, you are telling the
search engine where to go as well.URL's play a role in search engine optimization as well. While some URL's
can make a page inaccessible, others can help to optimize a page.
Pages created as the result of a search are called ‘dynamically generated'
pages. The answer to your query is encased in a web page designed to carry
the answer and sent to your computer. Often the page is not stored
anywhere afterward, because its unique content (the answer to your
specific query) is probably not of use to many other people. It's easier
for the database to regenerate the page when needed than to keep it around
(UC Berkley, 2004, p.1). Dynamically generated pages are not typically indexed because they can
fill search engine indexes with endless amounts of sometimes useless
information. A sure way to find out if a web site has been indexed, as
well as how many pages have been indexed, is to type in "site:" plus the
URL.
Example:
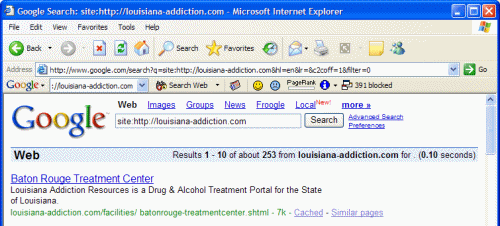
As evident by the result, the Louisiana Addiction site has 253 web pages
indexed. In the Yahoo! search engine, one can simply type in the URL
without the "site:" command to perform the same test.
For this project we focused on the area of addiction resources in the
state of Louisiana. We found that the state web site (Louisiana Office if
Addictive Disorders or "LOAD") was a perfect example of an online database
that was not accessible to the search engines.
The next step in our project was to begin a web site for Louisiana
Addiction Resources that would be accessible to the search engines. In
order to start the web site, we chose the name "Louisiana Addiction
Resources" and registered the URL "Louisiana-addiction.com".
The web site was designed from the ground up, with search engine
accessibility in mind. Parts of the URL for all pages were done
descriptively with page and directory names relevant to their content. The
same was done for the Title tags of the HTML pages as well. Where words
were included as image files in the web pages (such as the logo),
alternate text was used in the HTML; and the title of the site (Louisiana
Addiction Resources) was also written in plain text within a header tag on
the homepage. All hyperlinks, title tags, and header tags were done
descriptively as well, with hyperlinks in plain text.
Next, we added our resources to the web site. The agencies were also added
to the site with search engine accessibility in mind. Each agency included
in the site had a web page devoted to it with the name of the agency in
text on the page as well as in the title of the page.
Off-Page Optimization
PageRank is a concept that was developed by Google founders Sergey Brin
and Lawrence Page when they developed the Google search engine. "PageRank
is an excellent way to prioritize the results of web keyword searches. For
most popular subjects, a simple text matching search that is restricted to
web page titles performs admirably when PageRank prioritizes the results
(demo available at google.stanford.edu) (Brin, Page 1998)." The PageRank
concept is still in use on Google today, and is symbolized in their
directory and on their toolbar by a measurement of 0 - 10. Google uses a
graphic image of a green bar over a white bar to show the PageRank, or
"importance" of a web site in their directory.
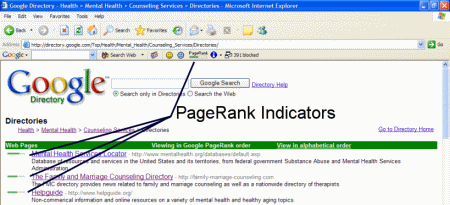
PageRank is currently updated almost quarterly for all web pages, and
"invisible web" or inaccessible pages never receive a PageRank score.
Using the Google toolbar (http://toolbar.google.com) is an unscientific
way of indicating whether or not a URL has been indexed. If the PageRank
indicator is all white or grey in color, it could mean that a site is
either brand new, has PageRank "0," is penalized, or not yet included in
Google's index. (Web pages are sometimes penalized when they are found to
be using techniques such as hidden text, doorway pages, and deceptive
redirects, aimed at deceiving a search engine). A PageRank score can be
from 0 - 10, with "10" being one of the most important pages on the web,
and "0" being one of the least important.
Google determines PageRank using many factors. Although search engines
don't make their algorithms public for obvious reasons, there is much we
know from what they have made public, past research, and experience in the
field. According to Google's web site:
PageRank relies on the uniquely democratic nature of the web by using its
vast link structure as an indicator of an individual page's value. In
essence, Google interprets a link from page A to page B as a vote, by page
A, for page B. But, Google looks at more than the sheer volume of votes,
or links a page receives; it also analyzes the page that casts the vote.
Votes cast by pages that are themselves "important" weigh more heavily and
help to make other pages "important" (Google, 2004).
With this knowledge about PageRank in mind, it is beneficial to a web
site's ranking in search results to have links to it from other web sites.
Buying links from online web directories, link advertising on other web
sites, exchanging links with other web sites, and requesting links from
other sites, are all common practices that build links to a web site and
help to improve that site's PageRank.
Anchor text is the text that is hyperlinked to another document. It is the
text that is contained within the hyperlink html tags. For example (in
html):<a href="http://www.example.com">Anchor Text</a>
Creates a hyperlink that looks like this:
Anchor Text
and is linked to the web site http://www.example.com.
Some words from Google's founders on anchor text:
The text of links is treated in a special way in our search engine. Most
search engines associate the text of a link with the page that the link is
on. In addition, we associate it with the page the link points to. This
has several advantages. First, anchors often provide more accurate
descriptions of web pages than the pages themselves. Second, anchors may
exist for documents which cannot be indexed by a text-based search engine,
such as images, programs, and databases (Brin, Page 1998, p.1).
They go on to say, "we use anchor propagation mostly because anchor text
can help provide better quality results. Using anchor text efficiently is
technically difficult because of the large amounts of data which must be
processed. In our current crawl of 24 million pages, we had over 259
million anchors which we indexed (Brin, Page 1998, p.1)."
IBM researchers as well have noted the importance of anchor text in the
indexing and ranking of documents:
Anchor text is typically very short, and provides a summarization of the
target document within the context of the source document being viewed.
Our main premise is that, on a statistical basis at least, anchor text
behaves very much like real user queries. For this reason, a better
understanding of the relationship between anchor text and their target
documents will likely lead to more effective results for a majority of
user queries (Eiron, McCurley 2002, p.1).
Knowing the importance of anchor text in search engine optimization, it is
important that we use descriptive text in the hyperlinks within our web
site as well as when asking other web sites to link to us. We incorporated
this strategy into the taxonomy of our web site. Here is the link
structure of the LAR site from the homepage to each parish's page:
Homepage (filename: index.shtml)
Treatment Facilities (text that links to
treatment-faclilities.shtml)
Louisiana Parish Treatment Facilities (filename:
treatment-faclilities.shtml)
Acadia Parish (text
that links to acadia-parish.shtml)
Allen Parish (text
that links to allen-parish.shtml)
Ascension Parish (text
that links to ascension-parish.shtml)
As one can see on the homepage (filename:
index.shtml), the anchor text
"Treatment Facilities" is used to link to the page with the parishes
listed. This was done with the intention of helping the page to show up
for searches like "Acadia Parish Treatment Facilities." It tells the
search engine that this page has to do with "treatment facilities."
Ideally, the link should tell the search engine that this page is about
the Louisiana Parishes and their treatment facilities, but usability must
come first; in other words, "treatment facilities" was chosen so that the
site's visitors will know where to go from the homepage to find their
resources (and because "Louisiana Parishes Treatment Facilities" is too
long and cumbersome for the text of a main menu item). It is a blend of
search engine optimization and usability.
Here is an example of how the parish pages are linked to their individual
resources:
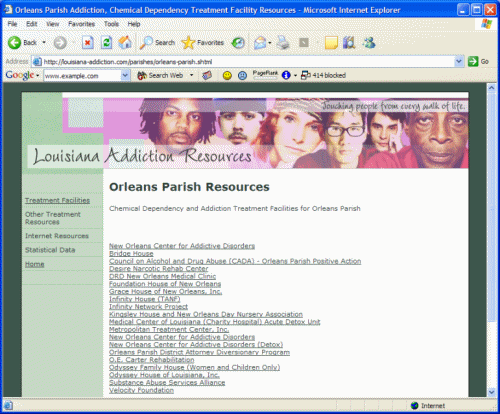
Each link on the page has descriptive anchor text, and brings the user to
the document it describes (the facility's database record). Quite
frequently, web sites use images to anchor hyperlinks to other documents.
Those images sometimes represent pictures and icons, but frequently have
words on them as well. The problem associated with using image files to
anchor hyperlinks, is that they frequently give no descriptive information
to the search engine spider because the web designer forgot to use
alternative text in the html document. "Alternative text" or "alt" text is
contained within the "alt" attribute of the image html tag, and it is used
simply, to describe the image file. Here is an example of the html that
would be used to insert a well-optimized image file (a picture of two dogs
playing in a yard):
<img src="dogs-playing.jpg" alt="Dogs Playing in a Yard">
"Alt" tags are used for other purposes as well, but only in the case of
images contained within hyperlinks are they presently indexed and used by
Google.
Anchor text should also be considered when asking other web sites to link
to your site. This applies for internet directory listings as well. Since
we wanted our web site to be found for the search "Louisiana Addiction
Resources," we asked for that link text in our directory listings rather
than making the title of the listing "LAR," as we refer to it in this
context. If we want the site to show up for both "LAR" and "Louisiana
Addiction Resources," it's beneficial to vary the link text occasionally.
For a good list of web directories that can help your site gain link
popularity, visit http://www.strongestlinks.com/directories.php.
Also worth mentioning are meta-tags. Meta tags are a part of the html head
section where an author can define the keywords they would like associated
with their web page, as well as a description. While there was a time when
the use of meta-tags was popular and had an affect on search engine
rankings, today their affect is minimal if anything at all. The problem
was that too many authors abused the use of meta-tags in order to get
their pages to rank well for irrelevant keywords. In response, search
engines stopped using meta-tags to affect rankings. Some still include
meta "descriptions" in their search results.
Historical Data
Historical data is a factor that has recently evolved into the ranking of
web sites in search results. In a recent Google patent application they
discuss many factors such as the age of links pointing to a site and the
length of time domain names are registered (Anurag, Cutts, et. al. 2005).
Many links that appear all at once pointing to a site can be seen as an
attempt to deceive a search engine through buying links from other web
sites. The document explains an analysis of a site's natural progression
of link building and rewards sites that adhere to that progression
(Anurag, et. al., 2005). This information is a likely explanation for some
phenomenon noticed by search engine optimizers over the past year which
they have labeled "the sanbox." The sandbox theory describes the fact that
many new web sites have not been able to rank well for competitive keyword
phrases, even though the sites were well-optimized, and had good links
pointing to them. Some describe the sanbox as lasting from 6 mos. to 1
year in length. While this information is useful and relevant to any new
web site, it is included here as a concept to be aware of when designing a
site; we do not wish to go into too much detail here, as it would stray
too far from the intended scope of the project. If the agency's need is to
target a competitive market that already has many well optimized sites in
the search results, it should hire an experienced SEO professional to do
the work.
Competitiveness of Search Terms
Not all search terms are created equal! Some phrases are more common than
others, therefore statistically; a web page has less of a chance of
showing up on the first page of results when the topic it covers is
something very common and on millions of other web pages.
This competitiveness of search terms also applies to phrases that are
commercial in nature. Wherever there is money to be made on the web, there
are web site owners trying to show up in search results. This leads to a
competitiveness that may exist regardless of the commonality of the word
or phrase. Commercial competitiveness can hinder a social service oriented
web site's ability to rank well for the search terms they target. One
advantage that social service agencies have, however, is that they are
more likely to be able to get other web sites to link to their site free
of charge due to the "helpful" nature of their services.
Participants
The participants in the project are Christopher C. Hartwell, Parker H.
Sternbergh, the LOAD web site, as well as all substance abuse clinics,
treatment centers, and prevention programs that were included in the site.
Other stakeholders are internet users who seek the information the site
provides through search engines, either directly, or those who happen upon
the site by chance as well as internet users in general, who all have an
opportunity to happen upon this web site.
Data Analysis
The final method used to show the effectiveness of our project was to
collect information from the server logs contained on the computer that
hosts the LAR web site. In particular we extracted query strings that were
typed into search engines by users, which resulted in that user finding
the data contained within our web site. The LAR site (at the time of this
project) was hosted on a Unix server by
Aplus.net of San Diego,
California. The statistical program used to extract the data from the
server logs was Mach5 Analyzer version 4.1.5 created by
Mach5 Enterprises,
LLC. The data shown here come from server logs that span a 31 day period
from March 16, 2005 to April 16, 2005. The LAR web site has been online in
an uncompleted form starting on November 5, 2004. All of the agency data
was added between February and March of 2005.
The following table is a 31 day list of keyword phrases that were typed
into search engines which resulted in that internet search engine user
entering the LAR web site. The number to the right represents the number
of times each phrase was used, and the search engine listed is the
referring site.
Click Here for Search
String Data
The above search strings are all associated with text contained within the
LAR web site.
To compare the site's traffic before and after it was crawled by the
search engines produces a clear and predictable result since the site was
promoted by no other means than the DMOZ.org link. Prior to being indexed,
the site had an average of 1 visitor per day (in November 2004), and after
being indexed it maintained a more steady stream of traffic, which has
increased since November 5, 2004 to where it is now at 43 visitors per
day. The following chart depicts the site's traffic from the beginning to
where it stands today. "Visits" are the number of unique users that visit
the site.
Summary by Month
|
|---|
| Summary by Month |
|---|
|
|---|
| Month |
Daily Avg |
Monthly Totals |
|---|
| Hits |
Files |
Pages |
Visits |
Sites |
KBytes |
Visits |
Pages |
Files |
Hits |
|---|
|
|---|
| Apr 2005 |
211 |
165 |
123 |
43 |
451 |
22265 |
824 |
2346 |
3147 |
4025 |
| Mar 2005 |
161 |
121 |
110 |
32 |
496 |
25889 |
992 |
3417 |
3780 |
4993 |
| Feb 2005 |
150 |
56 |
35 |
13 |
174 |
14942 |
374 |
1006 |
1589 |
4206 |
| Jan 2005 |
15 |
3 |
9 |
5 |
82 |
659 |
172 |
297 |
110 |
465 |
| Dec 2004 |
24 |
9 |
9 |
5 |
79 |
1214 |
169 |
293 |
295 |
765 |
| Nov 2004 |
71 |
17 |
5 |
1 |
19 |
1619 |
39 |
138 |
452 |
1848 |
|
|---|
| Totals |
66588 |
2570 |
7497 |
9373 |
16302 |
|---|
|
|---|
Findings / ResultsAlthough the web site is near completion and it has been indexed by all of
the major search engines, we have limited qualitative data to analyze. We
do know to some degree, that our project has been successful in its goal,
because it does show up for many search queries related to the site's
content. (Such as "Louisiana Addiction Resources" and queries involving
parish names, treatment facilities, etc.) The outcome of the project
demonstrates a method of building community resource web sites which are
accessible to search engines, and therefore, more accessible to the
public. The practical implications of this project are that community
resource organizations and government agencies who follow the guidelines
described herein, will be able to make their web sites more accessible to
the public.
The broad implications of this project are largely unknown at this point.
We would like to assume that, because community resource data is more
accessible, that consumers are finding the resources and putting them to
use. However, this can not be known without further study. Entrance and,
or exit polls on the web site would be potentially useful for finding out
more information about the internet users who visit the site. Potential
information worth gathering would be:
- Is this visitor a person seeking resources for themselves, or is he or
she a healthcare professional who is looking for resources in order to
help a client?
- Did the visitor find the resources they were looking for through our web
site?
- If the visitor did not find exactly what they were looking for, did they
find something comparable?
- Did the user actually follow through with a referral from our web site
(by contacting one of the agencies listed)?
- If a referral was followed through with, was it for the visitor, or for
another individual?
- Which visitors to the web site are more likely to follow through with
referrals (consumers or healthcare professionals)?
- Which visitors to the web site are more likely to follow through with
referrals (visitors who find the site through search engines, by word of
mouth, through links from other web sites, or other means)?
Many new questions are raised by this research, and the creators of this
project believe that the internet provides great opportunity for the
future of information and referral services for community service
organizations and the healthcare profession.
Limitations
The solution we have employed to search engine accessibility may not be
the most efficient solution for every web site. Our solution requires
updating the database separately from the web directory. There are
however, many other ways to make invisible web databases more accessible,
depending on the database technology in use. For some web servers, what's
called a mod_rewrite can be done in order to make the URL's created by the
server appear to be static to the search engine (Whalen, 2004). As Jill
Whalen (2004) points out in her newsletter, mod_rewrite may not always be
necessary as search engines are increasingly getting better at indexing
dynamic content. What is currently necessary is that there is some form of
static hyperlink to the content, dynamic or not. The use of the scripting
language PHP (Hypertext Preprocessor) has become a very efficient means
for interfacing a database with html content, and can be done in ways that
are invisible to the search engine. PHP is quickly becoming the search
engine friendly method of choice for implementation of database driven web
sites among search engine optimizers.
A limitation to the visibility of the LAR web site in search results is
the fact that it is relatively new, and no money has been spent promoting
the site. The stats obtained for this project are a result of the site
being initially found and indexed by the search engines through a free
DMOZ.org directory listing. Were the site promoted more through online
directory listings and links from other web sites, it would have ranked
higher for more competitive search terms.
Another limitation of this project was the fact that our analyses of
results were limited due to the fact that we only have statistics from the
LAR web site. Even if we could get stats from the LOAD web site, there
would be too many extraneous variables to account for the traffic the site
receives to make a real comparison. Our original project sought
cooperation with Via Link to make some of their data accessible, a project
that could have been measured using before and after comparisons; however,
Via Link never followed through with providing us with the sample data.
Since the LAR site has been accessible from the start, we don't have a
good opportunity to make a before and after comparison with its
statistics.
The information contained herein is as current and up-to-date as we could
provide. Search engine technology changes at a rapid pace in order to keep
up with the ever-expanding world wide web, and in order to provide
searchers with the most relevant results. Time sensitivity of research
data is an important consideration when implementing a web site, because
what was important one or two years ago (like meta-tags), can be near
irrelevance today.
Discussion
We live in a time when many people begin their search for services on the
internet (Baker, et. al., 2003). Searching the internet is a private and
easy way to begin to collect information and resources needed to help
solve many problems. Consumers may not be aware that an invisible web
exists; therefore, an agency that provides community services should take
care to be listed on a web page that is accessible to search engines and
avoids the problem of becoming a part of the invisible web. Invisible web
databases, such as LOAD discussed earlier, are useful to the public who
begin their search or find their way to the LOAD web site; however, search
engine accessible databases provide enhanced efficiency in making
resources available to the public by allowing them to be included in their
index as well. As organizations become more aware of search engine
accessibility as an issue, newer and better solutions will be implemented;
and ideally, more community resources will fall into the hands of the
people who need them.
References
Anurag, Cutts, Dean, Haahr, Henzinger, Hoelzle, Lawrence, et. al. (2005).
Information retrieval based on historical data. U.S. Patent and Trademark
Office, Patent Application Full Text and Image Database. Retrieved April
16, 2005 from
http://appft1.uspto.gov/netacgi/nph-Parser?
Sect1=PTO2&Sect2=HITOFF&p=1&u=%2Fnetahtml%2FPTO%2Fsear
ch-bool.html&r=1&f=G&l=50&co1=AND&d=PG01&s1=2005007
1741&OS=20050071741&RS=20050071741.
Baker, L., Wagner, T., Singer, S., Burndorf, K. (2003). Journal of the
American
Medical Association. 289 (18): 2400-2406.
Brin, S., Page L. (1998). The Anatomy of a Large-Scale Hypertextual Web
Search
Engine. Computer Science Department, Stanford University, Stanford, CA
USA.
Davis, J. ( 2002). Disenfanchising the Disabled: The Inaccesibility of
Internet-Based Health
Information. Journal of Health Communication. 7: 355-361.
Eoron, N., McCurley, K. S., (2003). Analysis of Anchor Text for Web
Search. IBM Almaden Research Center. Retrieved April 16, 2005 from
http://www.almaden.ibm.com/cs/people/mccurley/pdfs/anchor.pdf.
Google (2004). Our Search: Google Technology. Retrieved April 16, 2005
from http://www.google.com/technology/.
Google (2005). Google. Retrieved April 16, 2005 from
http://www.google.com.
Joachims, T. (2002). Optimizing search engines using clickthrough data.
Proceedings of the ACM Conference on Knowledge Discovery. USA, 2002
Lawrence, S., Giles, C. L., (2000). Accessibility of information on the
Web. Association of Computing Machinery v.11, n.1, pp. 32-39.
Nielsen//Netratings (2004). One in Three Americans Use a Search Engine,
According to Nielsen//Netratings. Retrieved April 16, 2005 from
http://www.nielsen-netratings.com/pr/pr_040223_us.pdf
Nielsen//Netratings (2005). Majority of Online Searchers Use Multiple
Search Engines, Pointing to a Fluid Competitive Landscape, According to
Nielsen//Netratings. Retrieved April 16, 2005 from
http://www.netratings.com/pr/pr_050228.pdf
Raghavan, S., Garcia-Molina, H. (2000) Crawling the Hidden Web. Computer
Science Dept., Stanford University. Retrieved April 16, 2005 from
http://dbpubs.stanford.edu:8090/pub/2000-36.
Silverrstein, C., Henzinger, M. (2002). Analysis of a Very Large Web
Search
Engine Query Log. Palo Alto: Google.com.
Sullivan, D. (2002) How to Use HTML Meta Tags. SearchEnginewatch Dec. 5,
2002 Retrieved April 16, 2005 from
http://searchenginewatch.com/webmasters/article.php/2167931
Sullivan, D. (2005). Neilson NetRatings Search Engine Ratings,
SearchEngineWatch.,
January 2005. Retrieved April 12, 2005 from
http://searchenginewatch.com/webmasters/article.php/2167931.
UC Berkley Library (2004). Invisible Web: What it is, Why it exists, How
to find it, and Its inherent ambiguity. Regents of the University of
California. Retrieved April 16, 2005 from
http://www.lib.berkeley.edu/TeachingLib/Guides/Internet/InivisibleWeb.html
Whalen, J. (2004). High Rankings Advisor Issue 102: Preparing for Your SEO
Campaign - To Mod_Rewrite or Not. High Rankings Advisor - Issue No. 102
Retrieved April 16, 2005 from http://www.highrankings.com/issue102.htm
Bibliography
Anurag, Cutts, Dean, Haahr, Henzinger, Hoelzle, Lawrence, et. al. (2005).
Information
retrieval based on historical data. U.S. Patent and Trademark Office,
Patent
Application. Full Text and Image Database. Retrieved April 16, 2005 from
http://appft1.uspto.gov/netacgi/nph-Parser?Sect1=PTO2&Sect2=HITOFF&p
=1&u=%2Fnetahtml%2FPTO%2Fsearch-bool.html&r=1&f=G&l=50&co1=AND&d=PG01&
s1=20050071741&OS=20050071741&RS=20050071741
Baker,,Laurence,Wagner, Todd,,Singer,Sara,Burndorf,Kate. (2003). Journal
of the
American Medical Association. 289 (18): 2400-2406.
Banach, Mary,Bernat,Frances. Liability and the Internet : Risks and
Recommendations for Social Work Practice. (2000). Journal of Technology in
Human Services. 17 (2/3) : 153-171.
Barratt, Moira. (2003). Organizational Support for evidence-based practice
within child
and family social work: a collaborative study. Child and Family Social
Work: 8
(2): 143-151.
Baker,Laurence,Wagner, Todd,Singer,Sara,Burndorf,Kate. (2003). Journal of
the
American Medical Association. 289 (18): 2400-2406.
Brin, S., Page, L. (1998). The Anatomy of a Large-Scale Hypertextual Web
Search
Engine. Computer Science Department, Stanford University, Stanford, CA
USA.
Cravens, J. (2000). Virtual volunteering: online volunteers providing
assistance to
human service agencies. (2000). Journal of Technology in Human Services.
17(2/3): 119-136.
.
Davis, Joel. ( 2002). Disenfranchising the Disabled: The Inaccessibility
of Internet-Based
Health Information. Journal of Health Communication. 7: 355-361.
Eoron, N., McCurley, K. S., (2003). Analysis of Anchor Text for Web
Search. IBM Almaden Research Center. Retrieved April 16, 2005 from
http://www.almaden.ibm.com/cs/people/mccurley/pdfs/anchor.pdf.
Gardyn, R. (2002). Surfing For Health. American Demographics. 3: 14-15.
Gilfords, E.D. (1998). Social Work on the Internet: an introduction.
Social Work. 43
(3): 243-251.
Google (2005). Google. Retrieved April 16, 2005 from
http://www.google.com.
Google (2004). Our Search: Google Technology. Retrieved April 16, 2005
from http://www.google.com/technology/.
Heinlan, K., Welfel, E., Richmond, E., Rak, C. (2003).
The Scope of Web Counseling: A Survey of Services and Compliance With
NBCC Standards for WebCounseling. Journal of Counseling and Development.
81(1): 61-69.
Holden, G., Finn, J. (2000). Human Services Online: A New Arena for
Service
Delivery. Part II. Journal of Technology in Human Services. !7 (2/3):
295-297.
Joachims, T. (2002). Optimizing search engines using clickthrough data.
Proceedings of the ACM Conference on Knowledge Discovery. USA, 2002
Kibirige, H., Depalo, L. (2000). Information Technology and Libraries. 19:
1-13.
Lawrence, S., Giles, C. L., (2000). Accessibility of information on the
Web. Association of Computing Machinery v.11, n.1, pp. 32-39.
Mandl, K., Felt, S., Pena, B., Kohane, I. (2002). Archives of
Pediatrics and Adolescent Medicine. 154(5): 508-511.
Marks, Jerry D. (2000). Online Fundraising in the Human Services. Journal
of
Technology in Human Services, l1( 2/3) 137-152
McCarty, D., Clancy, C. (2002). Telehealth : implications for social work
practice.
Social Work. 47(2):153-161.
Meir, A. (2000). Offering Social Support via the Internet: A case Study of
an Online
Support Group for Social Workers. 17(2/3): 237-266.
Levine, J. (2000). INTERNET: a framework for analyzing online human
service
practices. Journal of Technology in Human Services. 17 (2/3): 173-192.
Nielsen//Netratings (2005). Majority of Online Searchers Use Multiple
Search Engines, Pointing to a Fluid Competitive Landscape, According to
Nielsen//Netratings. Retrieved April 16, 2005 from
http://www.netratings.com/pr/pr_050228.pdf
Nielsen//Netratings (2004). One in Three Americans Use a Search Engine,
According to Nielsen//Netratings. Retrieved April 16, 2005 from
http://www.nielsen-netratings.com/pr/pr_040223_us.pdf
Patterson, D. (1996). An electronic social work knowledge base: a strategy
for
global information sharing. International Social Work. 39:149-61.
Powell, T., Jones, D., Cutts, D. (1998). Web site engineering:
beyond Web page design. New Jersey: Prentice Hall.
Price, G., Sherman, C. (2001). The Invisible Web: Uncovering Information
Sources Search Engines Cant See. Internet: Cyberage Books.
Raghavan, S., Garcia-Molina, H., (2000) Crawling the Hidden Web. Computer
Science
Dept., Stanford University. Retrieved April 16, 2005 from
http://dbpubs.stanford.edu:8090/pub/2000-36
Richie, H., Blanck, P. (2003). The promise of the Internet for disability:
a
study of on-line services and web site accessibility at Centers for
Independent
Living. Behavioral Science & the Law. 21(1): 5-23.
Safran, Charles (2003). The collaborative edge: patient empowerment for
vulnerable
population. International Journal of Medical Informatics. 69(2/3):
185-191.
Schultz, J.A., Frncisco, S.B., Wolff,T, et al. (2000) The Community Tool
Box:
Using the Internet to Support the Work of Community Health and
Development.
Journal of Technology in Human Services. 17(2/3):267-293.
Silverrstein, C., Henzinger, M. (2002). Analysis of a Very Large Web
Search
Engine Query Log. Palo Alto: Google.com.
Sullivan, D. (2002) How to Use HTML Meta Tags. SearchEnginewatch Dec. 5,
2002 Retrieved April 16, 2005 from
http://searchenginewatch.com/webmasters/article.php/2167931
Sullivan, D. (2005). Neilson NetRatings Search Engine Ratings,
SearchEngineWatch., January 2005. Retrieved April 12th,2005 from
http://searchenginewatch.com/webmasters/article.php/2167931.
Sullivan, D. (2005). Share of Searches: April 2004. SearchEnginewatch
Retrieved
April 12th,2005 from http://searchenginewatch.com/reports/
article.php/2156451
Sullivan, D. (2005). Share of Searches: December 2004. SearchEngineWatch.
Retreived April 12th from http://searchenginewatch.com/reports/
article.php/2156451.
UC Berkeley Library (2004). Invisible Web: What it is, Why it exists, How
to find it, and its inherent ambiguity. Regents of the University of
California. Retrieved April 16, 2005 from
http://www.lib.berkeley.edu/TeachingLib/Guides/Internet/InivisibleWeb.html
UC Berkeley Library (2004). Meta-Search Engines. Regents of the University
of California. Retrieved April 16, 2005 from
http://www.lib.berkeley.edu/TeachingLib/Guides/Internet/Meta-Search.html
WebWorkshop (2004). Google's PageRank Explained and How to Make the Most
of It.
Retrieved from http://www.webworkshop.net/pagerank_calculator.php.
WebWorkshop (2004). Search Engine Optimization (SEO) - the basics (how to
improve
your search engine rankings. Retrieved March 15, 2005 from
http://www.webworkshop.net/pagerank_calculator.php.
Wyatt, Jeremy. (1997). Commentary: measuring quality and impact of the
world wide
web. Information in Practice. British Medical Journal. 314: 1879.
Appendix
Anchor Text- The text that is used to link from one web document to
another.
Black Hat Search Engine Optimization- Search engine optimization
strategies that attempt to deceive or mislead the search engine.
Crawler or Spider- A program that automatically retrieves web pages.
Spiders are used to feed pages to search engines. It's called a spider
because it crawls over the web from hyperlink to hyperlink.
Database- A collection of information organized in such a way that a
computer program can quickly select desired pieces of data.. An electronic
filing system. Traditional databases are organized by fields, records and
files. A field is a single piece of information; a record is one complete
set of fields; and a file is a collection of records.
Dynamic Pages- Web pages that are actively generated by the server upon
the user's request. Most often they are generated in response to database
searches. Dynamic pages are the opposite of static web pages, which are
documents that reside in their full form on the server at all times.
HTML- Short for Hypertext Markup Languages used to create documents on the
World Wide Web..HTML defines the structure and layout of a web document by
using a variety of tags and attributes.
Proximity- The degree of separation of words within a document.
Hyperlink- An element in an electronic document that links to another
place in the same document or to an entirely different document.
Hyperlinks bring the user to the linked document by way of a mouse click.
Invisible web- that part of the web that cannot be indexed by search
engines. One of the most common reasons that a Web site's content is not
indexed is because of the site's use of dynamic databases. Dynamic
databases can trap a spider. Web pages can also fall into the invisible
Web if there are no links leading to them, since search engine spiders
typically crawl through links that lead them from one destination to
another.
Off-Page optimization- Factors that affect a document's search engine
ranking from outside of that document.
On-Page optimization- Factors that affect a document's search engine
ranking from within the document.
Meta tag- A part of the head section of an HTML document that provides
information about a web page. Unlike normal HTML tags, meta tags do not
affect how the page is displayed. Instead, they provide information such
as who created the page, how often it is updated, what the page is about,
and which keywords represent the page's content.
PageRank- Google's proprietary method for ranking web pages. A measure of
"importance" of a web page.
Private Network- A network that has limited access to it's pages.
Query Strings- Query strings come into being when a user types in a search term(s). At that point the search engine or database driven web site will
create a dynamic URL based upon the query. Query strings typically contain
? and % characters. They can sometimes be a barrier to search engine
spiders.
Search Engine- A program that searches documents for specified keywords
and returns a list of the documents that, ideally, best match the user's
query. Examples of search engines are Google and Alta Vista. Typically, a
search engine works by sending out a spider to retrieve as many documents
as possible. These documents are then indexed based on their content.
Search Engine Optimization- the process of helping a document to show up
in search engine results for queries related to its content.
Session ID- The identifier for a specific session completed by a specific
user. Session ID's are contained within the URL's of dynamic web sites and
can sometimes be a barrier to search engine spiders.
Static Page- A page that is fixed and not capable of action or change. A
web site that is static can only supply information that is written into
the HTML and this information will not change unless the change is written
into the source code. When a web browser requests the specific static web
page, a server returns the page to the browser and the user only gets
whatever information is contained in the HTML code. In contrast, a dynamic
web page contains content that a user can interact with, such as
information that is tied to a database.
URL- Short for Uniform Resource Locator, the global address of documents
and other resources on the World Wide Web. The first part of the address
indicates what protocol to use, and the second part specifies the IP
address or the domain name where the resource is located. Typically
appearing like "http://www.example.com."
Visible Web- The part of the Web that a search engine is able to access
with a web crawler.
White Hat Search Engine Optimization- Search engine optimization
strategies which attempt to influence a search engine to rank a document
high in the search results for queries related to its content. "White Hat"
optimization techniques do not attempt to deceive the search engine.
|



 Your Privacy Choices
Your Privacy Choices